

LynxScribe is an intelligent multilingual chatbot that enables companies to utilize OpenAI's ChatGPT for answering questions related to their products and services for their customers. It also uses Lynx Graph AI in some scenarios to answer complex questions. On Lynx Analytics' website, you can try a demo version of LynxScribe that was created in a few weeks by our data scientists while exploring the opportunities of Large Language Models.
In the background, we have already started implementing a more complex solution based on the specific needs of customers in the pharmaceutical and telecommunications space.
The Basics of Intelligent Chatbots
The majority of intelligent chatbots that answer questions from an internal knowledge base work in the following way (as documented in OpenAI's API):
-
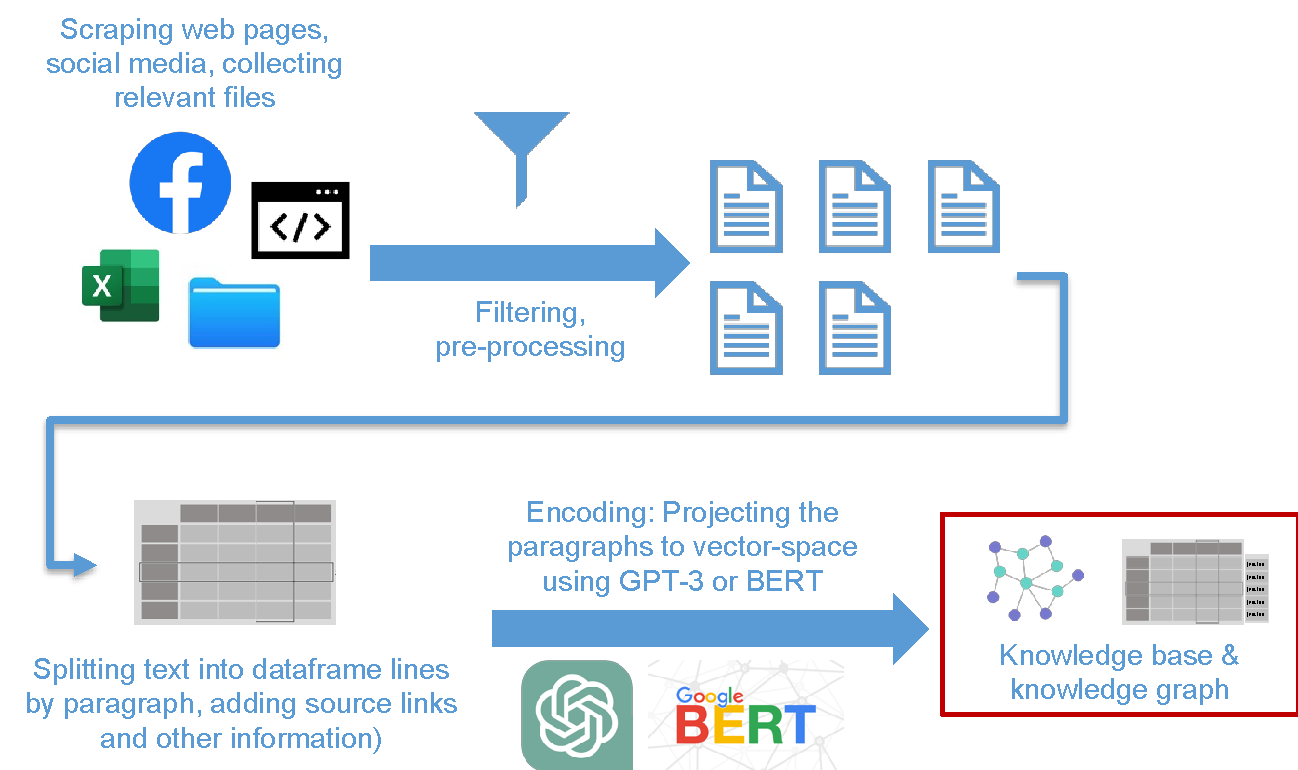
Step 0: Collect all files that can be useful for the chatbot and convert them to text files (e.g., you can export/crawl your webpage, collect all your pdf brochures).
-
Step 1: Split all the text files from step 0 into small pieces of texts (such as 200-500-word paragraphs).
-
Step 2: Create a table that contains the original text and its vector representation (encoded by OpenAI's text-embedding-ada-002 model or any other, like BERT).
-
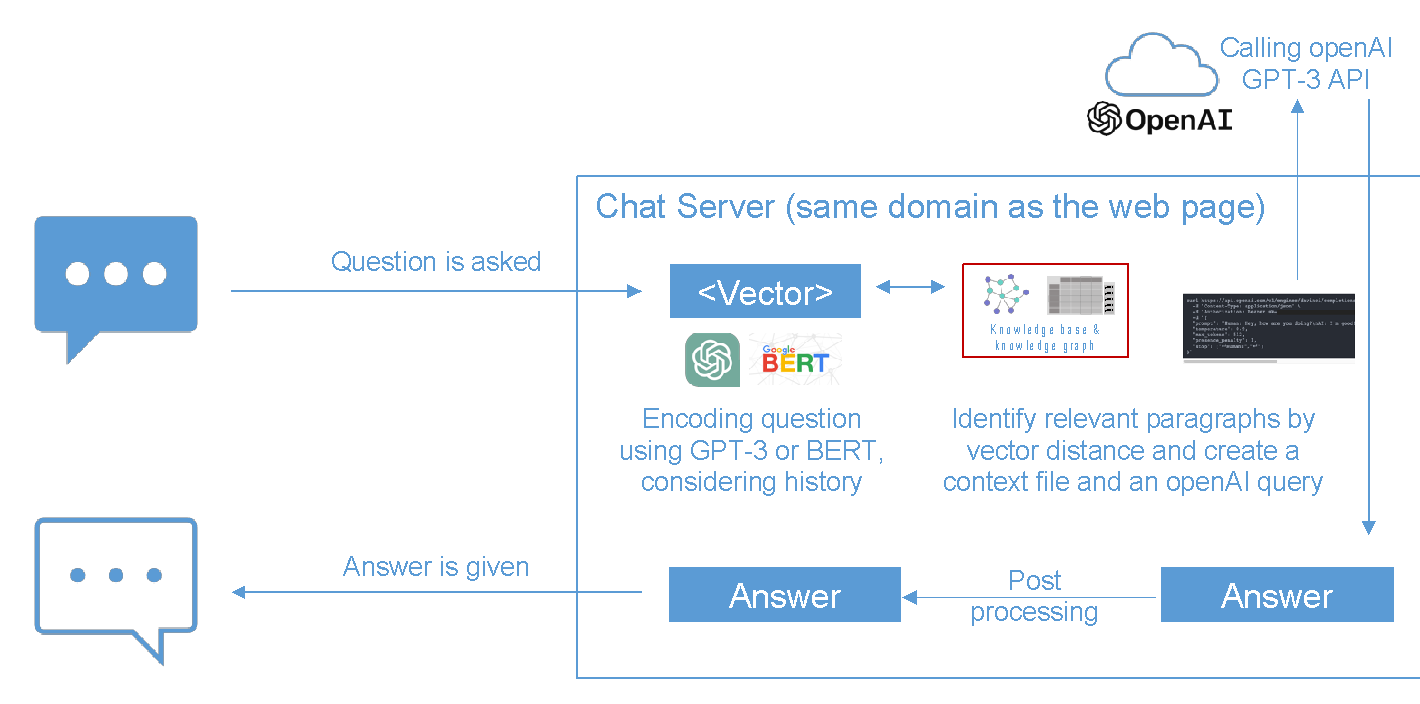
Step 3: When the user asks a question, translate their question to a vector (using the same method used in step 2).
-
Step 4: Find the top-n closest vectors to the question vector and copy their text to a context string. The overall word (token) size of the found text pieces should be within a limit.
-
Step 5: Create an OpenAI API call with the customer's question and the context string and ask it (basically ask ChatGPT) to answer the question based on the context.
-
Step 6: Perform some post-processing on the answer and send it back to the user (e.g., you can add links using the most relevant page of your website).
How LynxScribe is Different
The basics of LynxScribe are very similar to the typical workings of intelligent chatbots. However, LynxScribe tackles several further challenges, such as preprocessing various types of files for the knowledge base (including pictures, PDFs, DOCX, PPTX, HTML, etc.), splitting information at the right place, handling duplicated or contradictory information, and adding context to the latest question from the chat history. While you can use the LangChain python library for most of these tasks, in some cases it is better to build your own functions for getting the expected results.
The real difference lies in how we store the information. We use graphs. The embedding table, which contains the text and its vector representation for each 200-500 lines of paragraphs, is converted to "text nodes." We can add several other nodes to the graph if necessary (for instance, in the case of a customer service chatbot for a telco, daily updated prices and promotions can be added). As a next step, we can define different types of connections among these nodes.
For example, LynxScribe can create edges from the chat history, connecting those pieces of information (text nodes) that were answers to consecutive questions (so we'll know what information we need to add to the context besides the ones that answer the question). We can add several other nodes and edges from the metadata. For instance, if we're processing scientific articles, we can create author nodes, publication title nodes, or nodes for keywords, and connect the text nodes with these nodes if they are related. The first bit of graph analytics is used when adding a link to the end of the conversation as we consider their PageRank values while selecting the best fitting link to the answer. The PageRank values are calculated from the graph of the website where the information is scraped from.
How LynxScribe Uses Graph AI for Querying Knowledge Graphs
Since LynxScribe stores the knowledge base in a knowledge graph by adding extra nodes to the original text pieces (text nodes of 200-500 words) and defining some edges among them, an effective tool is necessary for gaining the necessary information related to the users’ questions. Lynx Analytics' flagship solution is LynxKite, a graph analytics software that we connected to a purpose-built graph database.
LynxKite can execute complex graph queries, from PageRank to modular clustering with built-in functions. Additionally, we created functions in LynxKite to make graph queries using plain English, which returns transformed graphs or a table with the requested information. LynxScribe uses this method to query complex knowledge graphs. To handle complex questions, templates are created that LynxScribe recognizes from the instructions, so it can make these complex queries more stable. The structure of the knowledge graph behind it is also suited for the task, with special nodes and edges created, and document summaries stored in several nodes and edges.
By organizing information into knowledge graphs, the chatbot can filter vast amounts of information into a digestible form that contains all necessary details to answer a question. The use of knowledge graphs is also beneficial from a transparency and ethical point of view, by making the internal logic of the AI system more explicit.
About the Infrastructure
LynxScribe can be used on all major cloud platforms, including Amazon AWS, Microsoft Azure, and Google Cloud Platform (GCP). If necessary, Neo4j can be used as a graph database platform, and smaller graphs can be stored in-memory. LynxScribe is scalable, meaning you only need to pay for the traffic you receive. The current solution can serve thousands of parallel sessions and scale up quickly.
Costs for API Calls and Infrastructure
The expenses associated with API calls and infrastructure determine the operational costs of running LynxScribe. The number of API calls and the size of the infrastructure required to handle daily questions both increase with a higher volume of inquiries. Currently, with a relatively small knowledge base and utilizing GPT-3.5, operational costs amount to approximately $1,000 for every 100,000 questions. While a larger knowledge base and greater number of questions could result in higher costs, they may not scale linearly. During the training phase, some API calls can be substituted with internal NLP models to reduce expenses. And since LynxScribe is compatible with any platform and large language model, it is possible to combine solutions to optimize API and infrastructure expenses.
Common Use Cases for LynxScribe
LynxScribe can support different use cases. The fact that natural language is being used to ask questions makes it a great fit for self-serve analytics. For example, it can help medical representatives (MRs) from pharmaceutical companies as they prepare for meetings with Health Care Practitioners (HCPs). MRs can ask complex questions such as, "Summarize all publications of my visited HCPs and their most common co-authors related to drug XYZ” and receive a summary of all related publications in under 30 seconds.
Customer service scenarios are also an obvious application for LynxScribe. By utilizing a company's internal knowledge base, LynxScribe can understand customers' questions and provide answers promptly. Depending on the setup, it can either answer questions directly or provide suggestions to customer service agents who can use or modify the suggestions or choose from variations. LynxScribe can also answer account-related questions while following security protocols to prevent sensitive information from being exposed. The chatbot learns from previous conversations, continuously improving its responses over time.
LynxScribe can also assist with inbound sales, especially in an e-commerce context. By analyzing ongoing conversations, LynxScribe can identify cross-selling opportunities and make relevant offers. In the background, LynxScribe learns from previous sales trials, developing better sales strategies. It can also be trained by the company's best salespeople by analyzing earlier sales conversations.
And this is just the beginning… The number of possible use cases is almost endless!
In conclusion, Lynx Analytics has leveraged OpenAI's ChatGPT and Lynx Graph AI to create an intelligent multilingual chatbot called LynxScribe. While it follows the typical working of intelligent chatbots, LynxScribe goes a step further by tackling challenges such as preprocessing various types of files for the knowledge base, handling duplicated or contradictory information, and adding context to the latest question from the chat history. The use of a knowledge graph to store information adds more value to the chatbot, making it more efficient in answering complex questions. Additionally, LynxScribe can be used on all major cloud platforms, making it scalable, and cost-effective.
