

Searching for relevant information within the vast landscape of clinical trials has historically been a challenging endeavor in the pharmaceutical industry. Traditionally, this process relied heavily on basic methods like word matching and simple scoring systems, which often struggled to capture the true essence and context of the data. However, recent technological advancements, such as ChatGPT and advanced indexing systems using vector embeddings, have transformed this landscape, offering more refined and effective approaches to retrieving information.
The Challenge of Traditional Methods
In the past, retrieving documents that accurately matched the needs of researchers, healthcare providers, and patients from databases like ClinicalTrials.gov was hindered by the limitations of methods such as TF-IDF (term frequency-inverse document frequency) and N-grams cosine similarity. These methods treated documents as collections of words and measured similarity based on the frequency of terms, often overlooking semantic relationships and deeper meanings.
For example, if someone searched for "heart attack treatment," documents discussing "myocardial infarction therapy" might be overlooked because these traditional methods failed to recognize that these terms are synonymous.
Similarly, understanding whether "Apple health benefits" refers to the fruit or the technology company was beyond the capabilities of these systems, leading to potential misinterpretations of search results.
Furthermore, complex queries like "long-term effects of high blood pressure medication on kidney function" posed significant challenges. Different phrasing or terminology in documents could lead to missed connections, impacting the accuracy and relevance of search results.
Embedding-based search, such as Word2Vec, GloVe, FastText, or even advanced OpenAI embeddings, captures the semantic meaning of words and phrases, enabling context-aware similarity measurements. However, these methods have limitations like:
- static knowledge, embeddings are fixed once trained, which means they cannot incorporate latest information or evolving contexts without re-training.
- while embeddings capture semantic similarity, they may overlook subtle relationships and deeper contextual meanings.
Introducing Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is a significant leap forward in how we search and retrieve information from clinical trial databases. By integrating advanced neural network models with vector embeddings and reranking, RAG enhances the accuracy, relevance, and efficiency of data retrieval. With RAG, the query undergoes a two-step process: retrieval and generation, first the system retrieves relevant documents from a large corpus, then the ai model synthesizes the information from these documents to generate a precise, contextually accurate response.
How RAG Addresses Limitations
- Dynamic Knowledge Integration: Embedding-based searches are static and cannot update with new information without retraining. RAG dynamically retrieves up-to-date documents, ensuring the latest research and findings are incorporated into the response. This allows for timely and relevant answers, keeping pace with the latest developments. Additionally, it eliminates the need to frequently retrain models, saving significant computational resources.
- Contextual Disambiguation: RAG leverages contextual embeddings to grasp polysemy—different meanings of the same word based on context. For instance, it can differentiate between "apple" as a fruit and "Apple" as a technology company, ensuring that search results align with the intended meaning.
- Conceptual Understanding: Traditional methods struggle to connect different phrases that refer to the same concept. RAG overcomes this by encoding relationships between concepts, allowing it to retrieve documents related to "diabetes management in elderly patients" and "strategies for controlling blood sugar levels in senior citizens" comprehensively.
- Handling Complex Queries: Complex queries that involve multiple concepts or long phrases are handled more effectively by RAG. It can understand and process the relationships within such queries, retrieving relevant documents even when the exact terminology varies.
- Negation and Semantic Similarity: One of the standout features of RAG is its ability to handle negation and recognize semantic similarities. It also recognizes semantic similarity between phrases like "pain relief medication" and "analgesic drugs," ensuring that all relevant information is retrieved regardless of specific wording.
Generation Phase:
- Contextual Embeddings: Retrieved documents are passed to the generative model (e.g., GPT-3) as context.
- Response Generation: The generative model uses this context to generate a coherent and relevant response to the query.
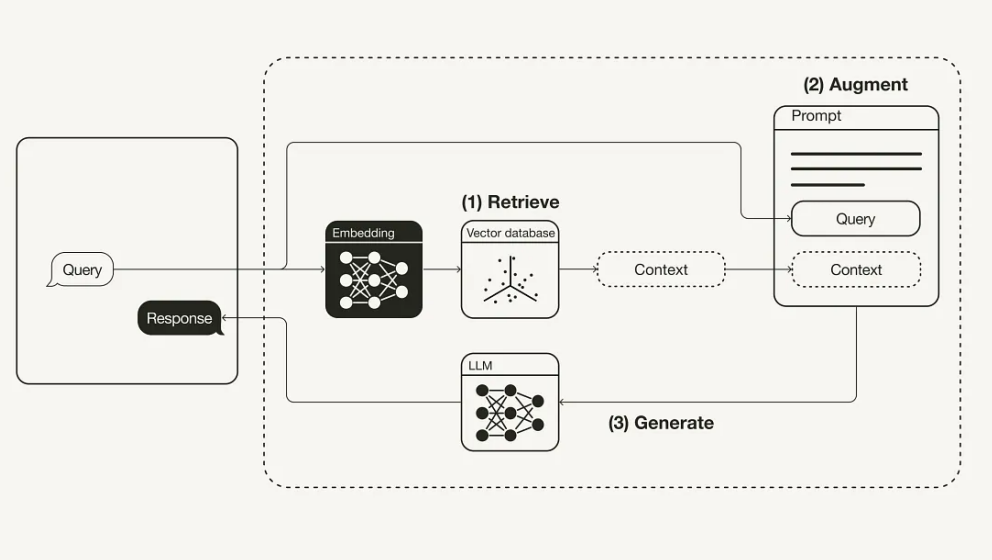
If you are interested in learning more about the technical details and going deeper into implementation options, including code examples, you can read this companion article.
Benefits of RAG
By combining the strengths of retrieval systems with the generative capabilities of advanced AI models, RAG offers:
- Improved Accuracy: Documents retrieved are more closely aligned with the user's intent due to enhanced semantic understanding.
- Efficiency: Faster retrieval times and reduced manual effort in sifting through large datasets.
- Usability: A more intuitive interface that delivers information in a comprehensible format, benefiting both experts and non-experts accessing clinical trial data.
Conclusion
Retrieval-Augmented Generation (RAG) represents a pivotal technological advancement in how we navigate and utilize clinical trial data. By overcoming the limitations of traditional search methods through advanced AI techniques, RAG ensures that researchers, healthcare providers, and patients can access accurate, relevant, and contextually meaningful information more effectively than ever before. As technology continues to evolve, the potential for RAG to further streamline information retrieval processes and drive advancements in pharmaceutical research and healthcare is immense, promising a future where accessing critical medical insights is both seamless and insightful.